Zip Archive for key prefix with S3 Object Lambda
S3 Object Lambda allows you to run code when an object is requested from S3. You can return a transformed version of the actual file stored in the S3 bucket, or you can even return objects that do not exist in S3 and are dynamically created at request time. In this post I show how you can create a zip archive containing all files under a specific key prefix.
The code
This github repository contains a CDK project with an example stack you can deploy into your own account.
Implementation
At a high level, you will need the following
An S3 bucket
A standard S3 Access Point
An execution role for the Lambda function
The Lambda Function
An Object Lambda Access Point that will be using the standard S3 Access Point as the Supporting Access Point
I create the standard access point and name it deepdive-zip-archive-standard-access-point
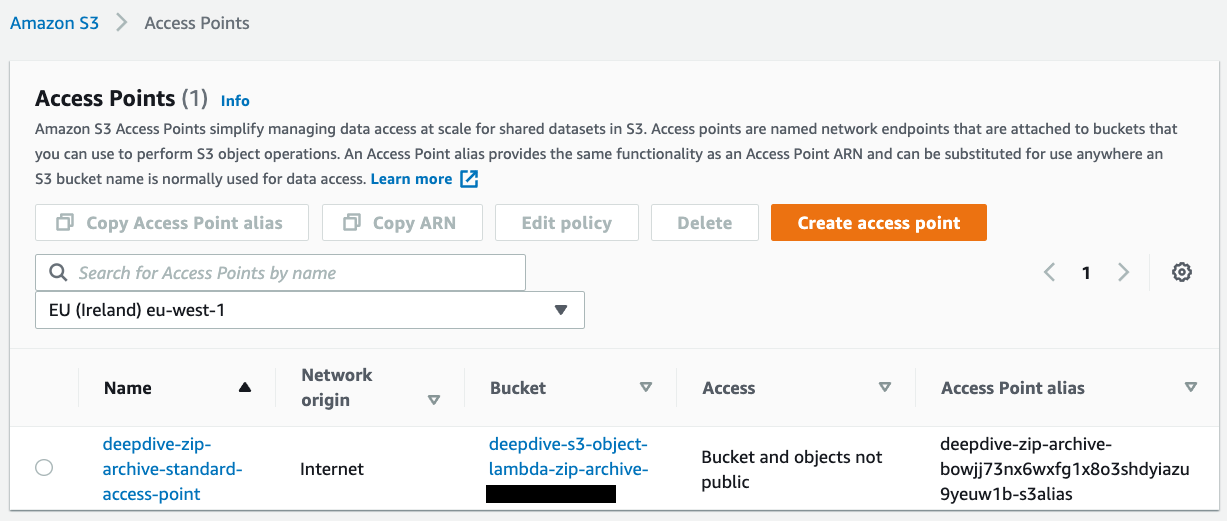
The role of the Lambda function will need to have the permissions to do s3-object-lambda:WriteGetObjectResponse so that it can write the response. Normally, that's all you need, because the function will receive an event with a field getObjectContext containing an inputS3Url that has embedded credentials to read the underlying object. However, in this case, we want to list the objects with the specific key prefix and read possibly more than one object. For that reason, we give the Lambda function read-only access to the bucket (via the supporting access point).
So the Lambda execution role will need the following policy (plus the AWSLambdaBasicExecutionRole managed policy).
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "s3-object-lambda:WriteGetObjectResponse",
"Resource": "*",
"Effect": "Allow"
},
{
"Action": [
"s3:List*",
"s3:Get*"
],
"Resource": [
"arn:aws:s3:<region>:<account-number>:accesspoint/deepdive-zip-archive-standard-access-point",
"arn:aws:s3:<region>:<account-number>:accesspoint/deepdive-zip-archive-standard-access-point/object/*"
],
"Effect": "Allow"
}
]
}
This is the Lambda function code itself:
import os
import boto3
import zipfile
from io import BytesIO
from urllib.parse import urlparse
ACCOUNT_ID = os.environ['ACCOUNT_ID']
ACCESS_POINT_ALIAS = os.environ['ACCESS_POINT_ALIAS']
s3_client = boto3.client('s3')
s3_resource = boto3.resource('s3')
s3_paginator = s3_client.get_paginator('list_objects')
def main(event, context):
object_get_context = event["getObjectContext"]
print(object_get_context)
request_route = object_get_context["outputRoute"]
request_token = object_get_context["outputToken"]
s3_url = object_get_context["inputS3Url"]
prefix = urlparse(s3_url).path[1:]
in_memory_zip = BytesIO()
with zipfile.ZipFile(in_memory_zip, mode='w', compression=zipfile.ZIP_DEFLATED) as zip:
page_iterator = s3_paginator.paginate(Bucket=ACCESS_POINT_ALIAS, Prefix=prefix)
for page in page_iterator:
if 'Contents' in page:
for entry in page['Contents']:
key = entry['Key']
body = s3_resource.Object(ACCESS_POINT_ALIAS, key).get()['Body'].read()
zip.writestr(key, body)
s3_client.write_get_object_response(
Body=in_memory_zip.getvalue(),
RequestRoute=request_route,
RequestToken=request_token)
return {'status_code': 200}
I am extracting the key of the requested object from inputS3Url. This key is used as the key prefix. I list all objects starting with the given prefix, and then read them one by one adding them to a zip archive in memory. At the end, I write the zip file at the output route using the output token (both provided in the event passed into the lambda).
Once I have created the standard access point and the lambda function, I can create the S3 Object Lambda Access Point
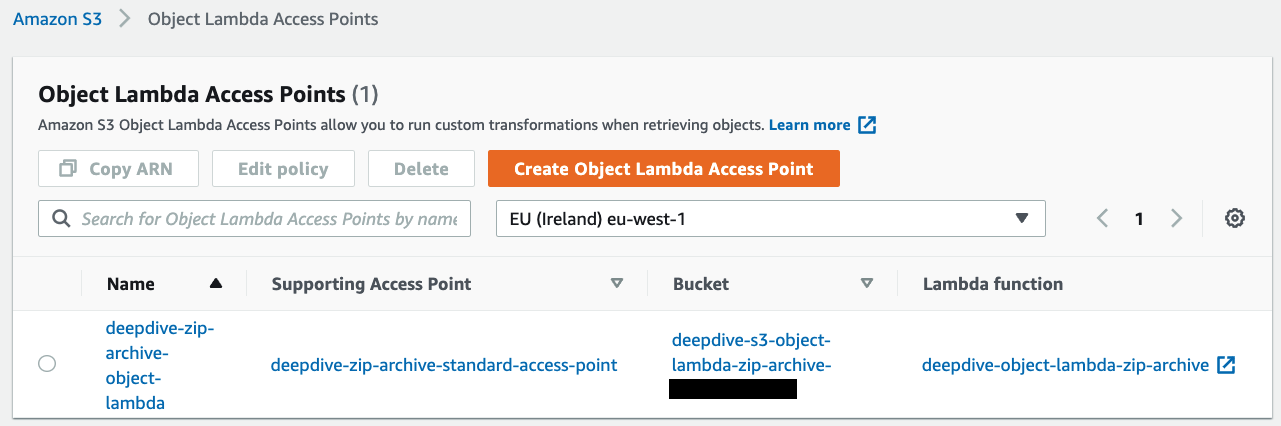
Testing it
I have populated the underlying S3 bucket with some files within different prefixes.
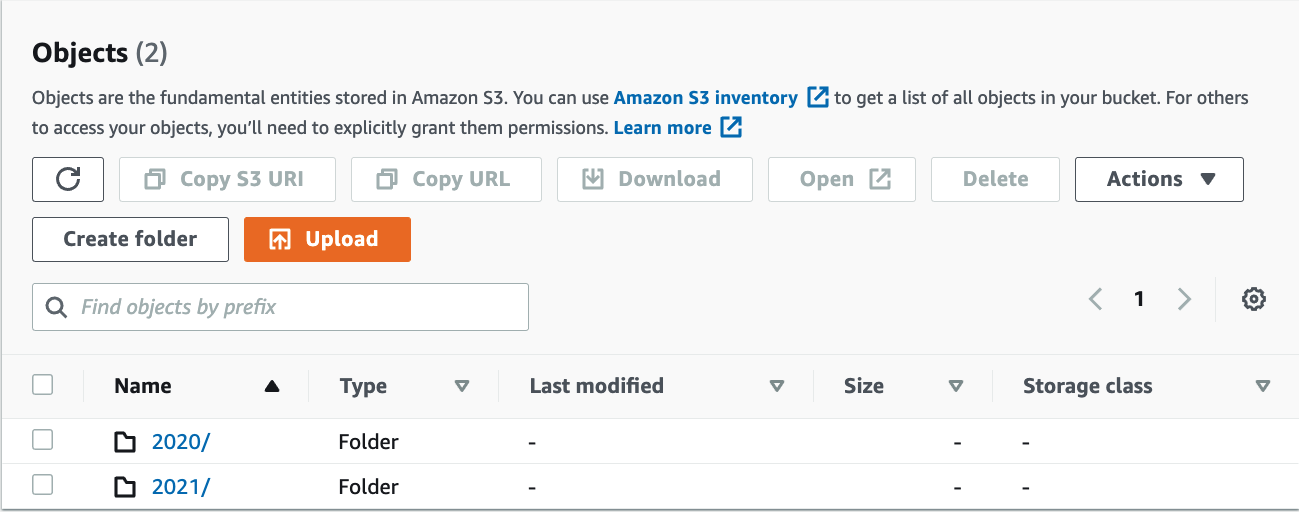
Now, it is just a matter of requesting a prefix as if requesting the specific key from S3. I am using the AWS CLI for this, and to make it work, I need to use the full ARN of the Object Lambda Access Point as the bucket parameter.
aws s3api get-object --key 2020 --bucket arn:aws:s3-object-lambda:<region>:<account number>:accesspoint/deepdive-zip-archive-object-lambda 2020.zip
In this case, I request the key 2020 that does not exist. The lambda function zips all objects with key starting with that prefix and returns the archive.
Limitations
With the specific implementation, because I am creating the zip file in memory, I am limited by the 10GB memory limit of Lambda.
Conclusion
With S3 Object Lambda we can dynamically create S3 objects at request time and this allows us to create, for example, a ZIP archive with all objects under a specific key prefix.