Spark Job on Serverless Kubernetes Cluster with Fargate
This post describes how to run Spark applications on a serverless Amazon EKS (Elastic Kubernetes Service) cluster with AWS Fargate.
It might be useful for understanding
Infrastructure as Code and how to create an EKS cluster with the AWS CDK in TypeScript
How to configure a cluster with serverless compute capacity provided by Fargate
How to install and configure the Spark Operator on EKS
How to deploy a Spark job and configure permissions to access an S3 bucket
GitHub Repo
The full project can be found in this GitHub repo. In the code below, you might see details that are specific to how I have structured and configured the project. The full repo might contain the answer to something that doesn't look right.
Creating the Cluster
Creating an EKS cluster with Fargate is as simple as
const cluster = new eks.FargateCluster(this, 'eks-cluster', {
vpc: props.vpc,
version: eks.KubernetesVersion.V1_21,
clusterName: `${props.deployment.Prefix}-cluster`,
endpointAccess: eks.EndpointAccess.PUBLIC_AND_PRIVATE.onlyFrom(...props.deployment.AllowedIpRanges)
});
props.deployment.AdminUserArns.forEach(userArn => {
const user = iam.User.fromUserArn(this, userArn, userArn);
cluster.awsAuth.addUserMapping(user, { groups: [ 'system:masters' ]});
});
In the configuration, I have included
Allowed CIDR ranges to access the endpoint
A set of users that are given master access
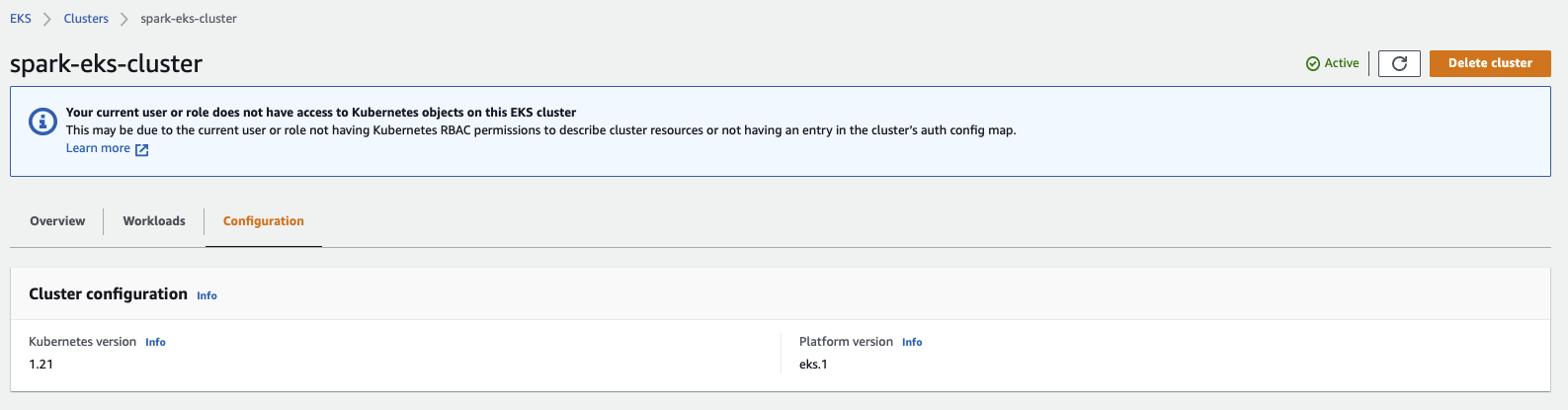
Without the second point, you will see the following message in the Management Console
Your current user or role does not have access to Kubernetes objects on this EKS cluster
This may be due to the current user or role not having Kubernetes RBAC permissions to describe cluster resources or not having an entry in the cluster’s auth config map.
or
Spark Operator
The cluster comes with a Fargate profile for pods running in the default namespace. The Spark operator will be installed in the spark-operator namespace. I create a Fargate profile for this namespace
const sparkOperatorNamespace = 'spark-operator';
const fargateProfile = props.cluster.addFargateProfile('spark-operator-fargate-profile', {
fargateProfileName: 'spark-operator',
selectors: [ { namespace: sparkOperatorNamespace }]
});
I install the Helm Chart for the Spark Operator
const sparkOperatorRelease = 'spark-operator-release';
const sparkOperatorChart = props.cluster.addHelmChart('spark-operator', {
chart: 'spark-operator',
release: sparkOperatorRelease,
repository: 'https://googlecloudplatform.github.io/spark-on-k8s-operator',
version: props.version,
namespace: sparkOperatorNamespace,
createNamespace: true,
wait: true,
timeout: cdk.Duration.minutes(15)
});
Pods will only be scheduled on Fargate if they are annotated with eks.amazonaws.com/compute-type: fargate. For that reason, I patch the deployment so that the Spark Operator controller can run on Fargate.
const sparkOperatorDeploymentPatch = new eks.KubernetesPatch(this, 'spark-operator-patch', {
cluster: props.cluster,
resourceName: `deployment/${sparkOperatorRelease}`,
resourceNamespace: sparkOperatorNamespace,
applyPatch: { spec: { template: { metadata: { annotations: { 'eks.amazonaws.com/compute-type': 'fargate' }} } } },
restorePatch: { }
});
sparkOperatorDeploymentPatch.node.addDependency(sparkOperatorChart);
Spark Service Account
I create a Service Account named spark to be used by the Spark application
const sparkServiceAccountName = 'spark'
const sparkServiceAccount = props.cluster.addServiceAccount('spark-service-account', {
name: sparkServiceAccountName,
namespace: sparkApplicationNamespace
});
I make sure that the Service Account has the right permissions so that the driver can launch pods for the executors.
const sparkApplicationNamespace = 'default';
const sparkRoleName = 'spark-role';
const sparkRole = props.cluster.addManifest('spark-role-manifest', {
apiVersion: 'rbac.authorization.k8s.io/v1',
kind: 'Role',
metadata: {
name: sparkRoleName,
namespace: sparkApplicationNamespace
},
rules: [
{
apiGroups: [""],
resources: ["pods"],
verbs: ["*"]
},
{
apiGroups: [""],
resources: ["services"],
verbs: ["*"]
},
{
apiGroups: [""],
resources: ["configmaps"],
verbs: ["*"]
}
]
});
sparkRole.node.addDependency(sparkServiceAccount);
const sparkRoleBinding = props.cluster.addManifest('spark-role-binding-manifest', {
apiVersion: 'rbac.authorization.k8s.io/v1',
kind: 'RoleBinding',
metadata: {
name: 'spark',
namespace: sparkApplicationNamespace
},
subjects: [
{
kind: 'ServiceAccount',
name: sparkServiceAccountName,
namespace: sparkApplicationNamespace
}
],
roleRef: {
kind: 'Role',
name: sparkRoleName,
apiGroup: 'rbac.authorization.k8s.io'
}
});
sparkRoleBinding.node.addDependency(sparkRole);
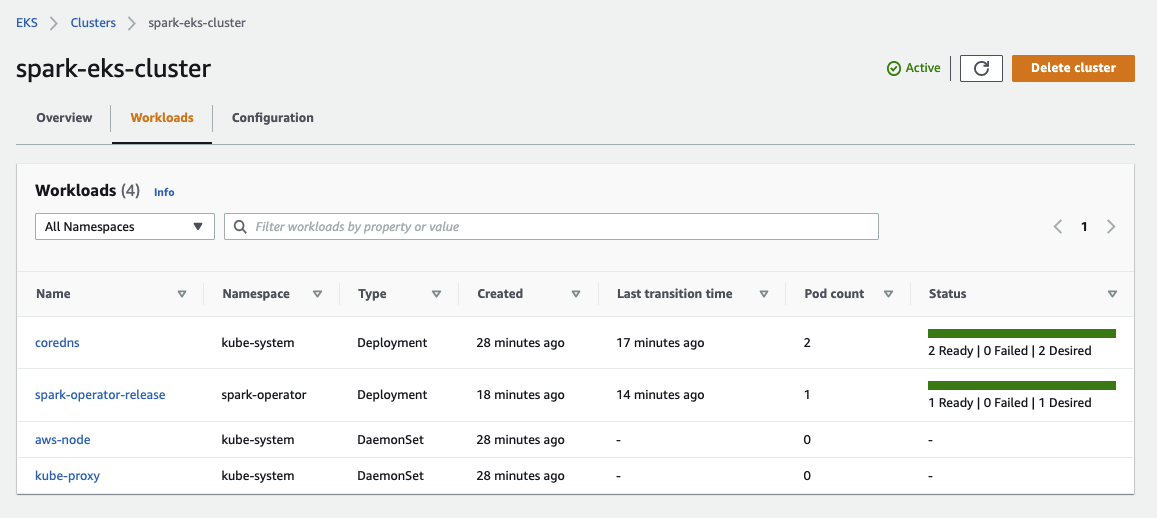
If you can see in the Management Console that the Spark Operator has 1 Ready pod, then everything has worked. Select your cluster and check under Workloads.
Kubectl configuration
The deployed CDK stack outputs the command to update your kubectl configuration and connect to the EKS cluster. It will look something like this
aws eks update-kubeconfig --name spark-eks-cluster --region eu-west-1 --role-arn arn:aws:iam::1234567890:role/spark-eks-core-stack-eksclusterMastersRoleCD54321A-RK2GQQ9RCPRO
IAM roles for Service Accounts
This is best described in the documentation but I will show you some of the pieces of the puzzle.
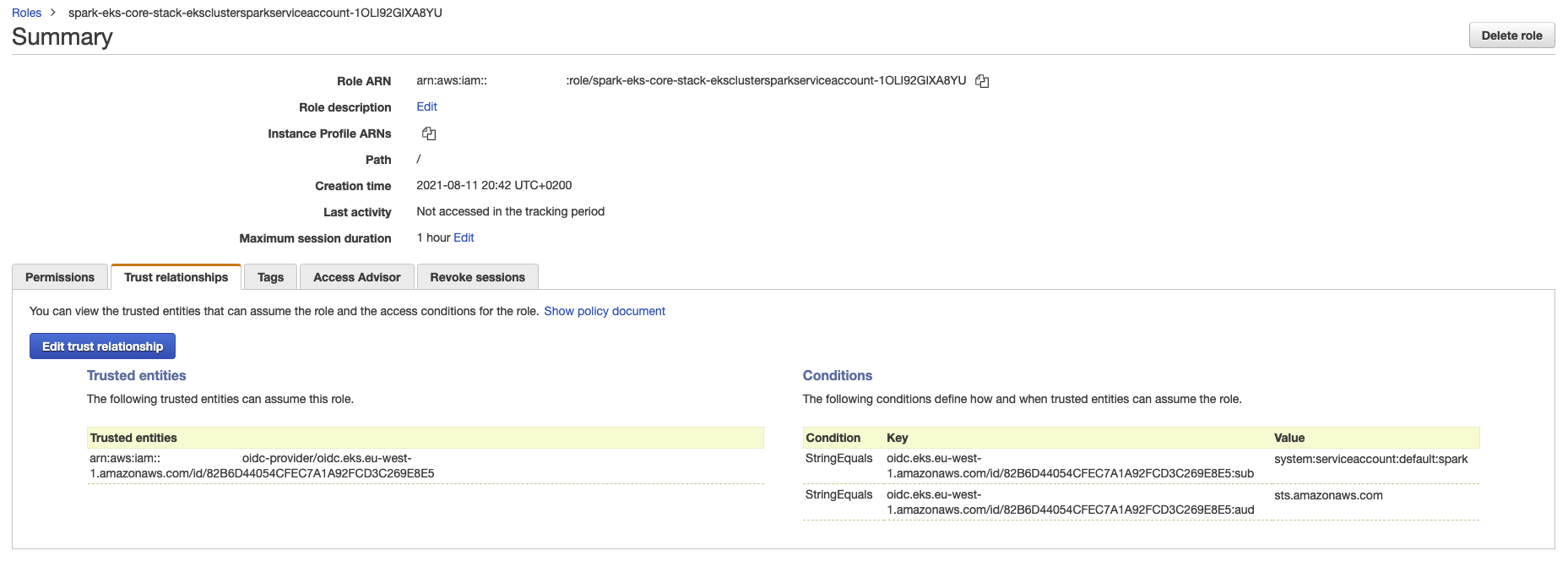
If I describe the service account with kubectl describe sa spark, then it is annotated with an IAM role

This role has a trust policy and it can be assumed by the OIDC provider of the cluster
This provider can be seen in Identity Providers within IAM
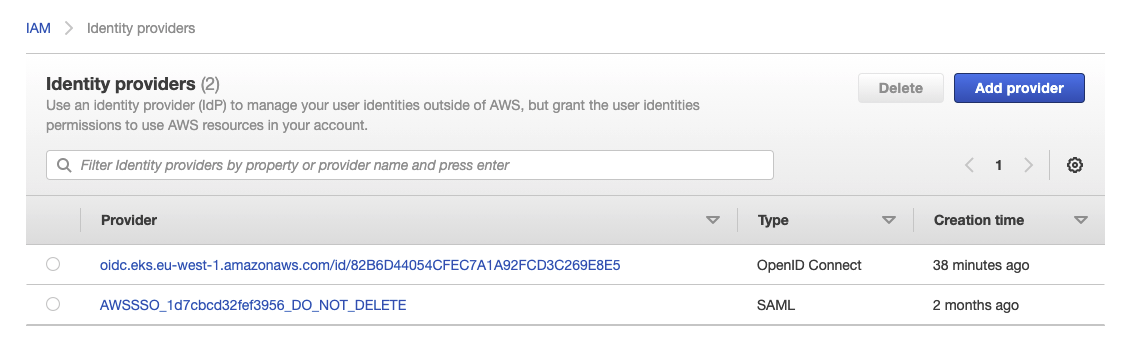
All this has been created automagically by the CDK.
Adding permissions to the Service Role
I can easily add permissions to the Spark Service Account like this (this is in a construct I call sparkOperator, see GitHub repo for the details).
sparkOperator.sparkServiceAccount.addToPrincipalPolicy(new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: ["s3:*"],
resources:[
dataLake.bucket.bucketArn,
dataLake.bucket.arnForObjects("*"),
]
}));
Running a Spark Job
As a test, I run a PySpark Job that reads and writes back to S3.
The
Dockerfileand the application code can be found hereSee also this post for building the base docker image.
I build the image
const image = new DockerImageAsset(this, `docker-image-asset-${props.jobName}`, {
directory: `./assets/docker-images/${props.jobName}`,
buildArgs: {
AWS_SDK_BUNDLE_VERSION: props.sparkConfig.AwsSdkBundleVersion,
HADOOP_VERSION: props.sparkConfig.HadoopVersion,
SPARK_VERSION: props.sparkConfig.Version
}
});
and I add the manifest to the cluster. I am running a SparkApplication but this could have also been a ScheduledSparkApplication.
props.cluster.addManifest(`spark-job-${props.jobName}`, {
apiVersion: 'sparkoperator.k8s.io/v1beta2',
kind: 'SparkApplication',
metadata: {
name: props.jobName,
namespace: 'default'
},
spec: {
sparkVersion: props.sparkConfig.Version,
type: 'Python',
pythonVersion: '3',
mode: 'cluster',
image: image.imageUri,
imagePullPolicy: 'Always',
mainApplicationFile: 'local:///opt/spark-job/application.py',
sparkConf: { },
hadoopConf: {
'fs.s3a.impl': 'org.apache.hadoop.fs.s3a.S3AFileSystem',
'fs.s3a.aws.credentials.provider': 'com.amazonaws.auth.WebIdentityTokenCredentialsProvider'
},
driver: {
envVars: props.environment ?? {},
cores: 1,
coreLimit: "1200m",
memory: "512m",
labels: {
version: props.sparkConfig.Version
},
serviceAccount: props.serviceAccount.serviceAccountName
},
executor: {
envVars: props.environment ?? {},
cores: 1,
instances: 2,
memory: "512m",
labels: {
version: props.sparkConfig.Version
}
}
}
});
It is important to specify the 2 hadoopConf settings above in order to access S3.
Starting times
The driver stayed 1 minute in the Pending state

then ContainerCreating

and 100 seconds later it was Running

The executors have been Pending for another 60 seconds

Then the first executor started creating

and later the second executor started creating

The first executor started running 3 minutes after the application was scheduled (age of the driver)

while the second executor took 2 minutes to start running (similar to the driver)

So all drivers were up and running almost 4 whole minutes after the job was scheduled.
Fargate pros and cons
The main advantage of Fargate is that you really pay for what you use. There is no need to manage and auto-scale servers. Also there is no need to efficiently pack your pods within container instances in order to minimise waste
The main disadvantage I see using Fargate out-of-the-box (without any optimisation), is that the startup time is up to 2 minutes. This means 2 minutes for the driver, and another 2 minutes for the executors, giving us a total of 3-4 minutes for the application to start. This might be acceptable or not depending on the workflow. For example, it might be acceptable for a batch job running hourly.
Conclusion
The Spark Operator allows us to run SparkApplications or ScheduledSparkApplications on Kubernetes. With Amazon EKS and AWS Fargate we can run Spark applications on a Serverless Kubernetes Cluster. The AWS CDK allows us to easily provision a cluster, install the Spark Operator and schedule Spark Applications in a reusable and repeatable way. Permissions can be set up to access resources in S3 via IAM roles associated to Service Accounts.