Spark Operator container Image for Amazon EKS
This is how to create the necessary docker images to run Spark on Amazon EKS (Elastic Kubernetes Service) using Spark on k8s Operator. This is because the provided images for Hadoop 3 did not work out of the box with the IAM role associated with the Service Account. This is necessary for example for reading and writing to S3.
Create Amazon ECR repositories
I store the base images in Amazon ECR but you can do the same with a different container registry if you wish.
In the AWS Management Console, navigate to Elastic Container Registry and create 2 repositories.
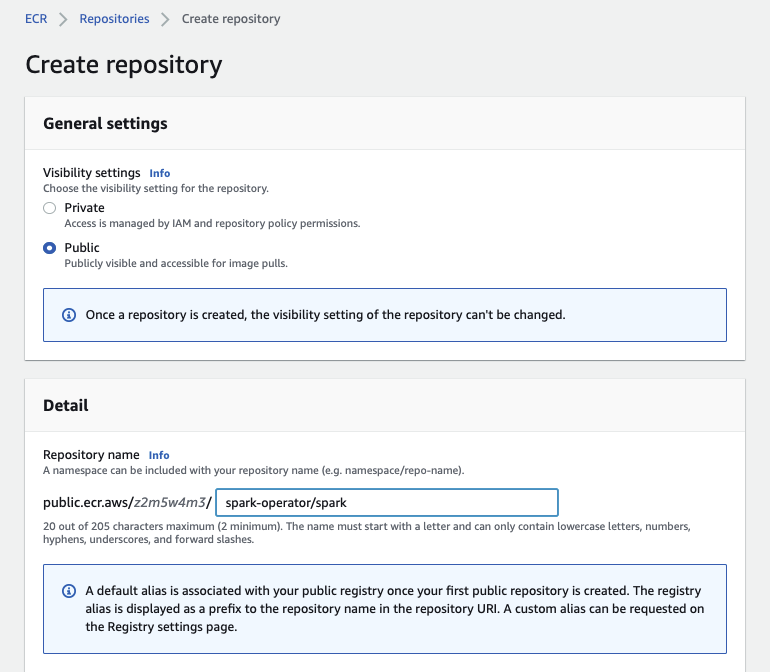
The repo names are expected to have specific names
<namespace>/spark<namespace>/spark-py
I used spark-operator as the namespace.
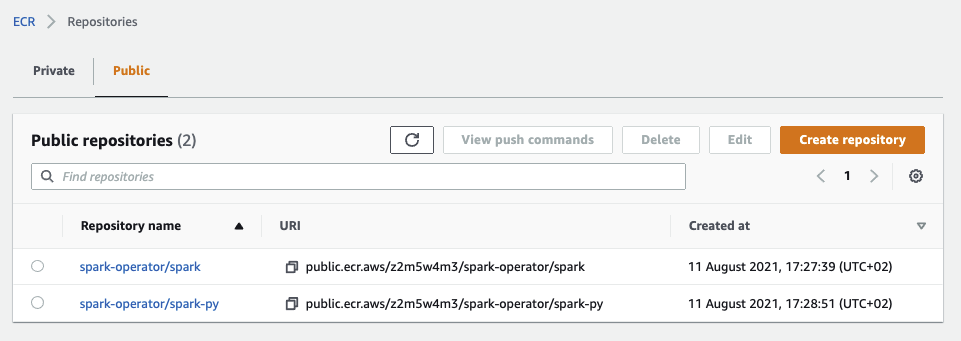
I choose to create public repositories, but you can create private repositories as well.
For public repos, you can log in to ECR with
aws ecr-public get-login-password --region us-east-1 | docker login --username AWS --password-stdin public.ecr.aws
for private repos, I login with
aws ecr get-login-password --region <region> | docker login --username AWS --password-stdin <account id>.dkr.ecr.<region>.amazonaws.com
Build Spark base image
I clone the Spark repository
git clone git@github.com:apache/spark.git
I checkout a specific version
git checkout v3.1.1
I build the project with a specific Hadoop version (3.3.1 in this case). It is important to build it with Kubernetes support by including the corresponding flag.
./build/mvn -Pkubernetes -Dhadoop.version=3.3.1 -DskipTests clean package
The Hadoop version dictates the version of hadoop-aws, which is also
3.3.1in this caseThis in turn dictates the version of aws-java-sdk-bundle, which is
1.11.901.A recent version of the AWS SDK is needed so that it supports the
com.amazonaws.auth.WebIdentityTokenCredentialsProvider.
I build and tag the docker image (including the python profile)
./bin/docker-image-tool.sh -r public.ecr.aws/z2m5w4m3/spark-operator -t v3.1.1-hadoop3.3.1 -p ./resource-managers/kubernetes/docker/src/main/dockerfiles/spark/bindings/python/Dockerfile build
I push the images
./bin/docker-image-tool.sh -r public.ecr.aws/z2m5w4m3/spark-operator -t v3.1.1-hadoop3.3.1 push
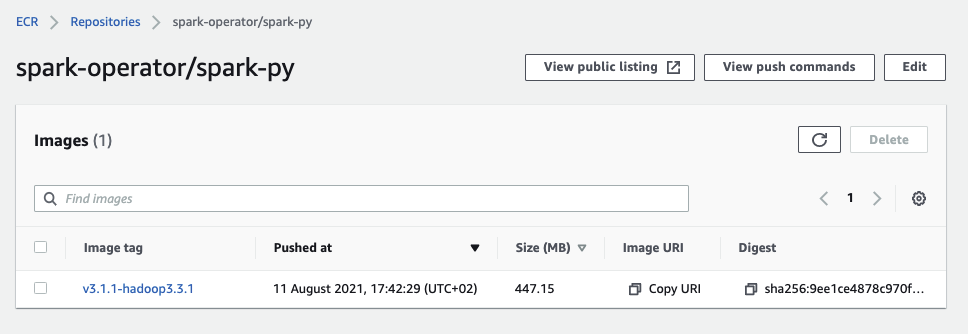
and the image tags appear on ECR
Build Spark application image
Finally, I build on top of the Spark base image a new docker image that additionally includes
the correct version of
hadoop-awslibrarythe correct version of
aws-java-sdk-bundleyour application code
For a PySpark application, here is an example Dockerfile, where application.py is stored beside the Dockerfile
ARG SPARK_VERSION=3.1.1
ARG HADOOP_VERSION=3.3.1
FROM ubuntu:bionic as downloader
ARG HADOOP_VERSION=3.3.1
ARG AWS_SDK_BUNDLE_VERSION=1.11.901
RUN apt-get update && apt-get install -y \
wget \
&& rm -rf /var/lib/apt/lists/*
RUN wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/${HADOOP_VERSION}/hadoop-aws-${HADOOP_VERSION}.jar -P /tmp/spark-jars/
RUN wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/${AWS_SDK_BUNDLE_VERSION}/aws-java-sdk-bundle-${AWS_SDK_BUNDLE_VERSION}.jar -P /tmp/spark-jars/
FROM public.ecr.aws/z2m5w4m3/spark-operator/spark-py:v${SPARK_VERSION}-hadoop${HADOOP_VERSION}
USER root
COPY --from=downloader /tmp/spark-jars/* $SPARK_HOME/jars/
COPY application.py /opt/spark-job/application.py
Similarly to the base image, you can push this to a private repository in ECR.
Running a Spark Job
I create a manifest file my-spark-app.yaml
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: my-pyspark-app
namespace: default
spec:
type: Python
pythonVersion: "3"
mode: cluster
image: "<URI of private ECR repository with docker image containing the spark application>"
imagePullPolicy: Always
mainApplicationFile: "local:///opt/spark-job/application.py"
sparkVersion: "3.1.1"
hadoopConf:
fs.s3a.impl: org.apache.hadoop.fs.s3a.S3AFileSystem
fs.s3a.aws.credentials.provider: com.amazonaws.auth.WebIdentityTokenCredentialsProvider
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 3.1.1
serviceAccount: spark
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 3.1.1
where the image should be set to the URI of your private ECR repo that holds the image from the previous section. It is important not to forget to include
spec:
hadoopConf:
fs.s3a.impl: org.apache.hadoop.fs.s3a.S3AFileSystem
fs.s3a.aws.credentials.provider: com.amazonaws.auth.WebIdentityTokenCredentialsProvider
The spark Service Account has an associated IAM role that permits access to S3 or other AWS resources. Creating an EKS cluster and Service Accounts can be easily done with AWS CDK. See this post for more details, or at this github repo.
Finally, I apply the manifest
kubectl apply -f my-spark-app.yaml
Conclusion
It is possible to use IAM roles to write to S3 from a Spark Job running with the Spark Operator. These roles are associated to a Service Account. For this, it is necessary to include a recent version of aws-java-sdk-bundle, which requires to build the Spark docker image from the source, with the necessary version of Hadoop.